
Word Ladder – Can you climb to the top? (Part I)
Word Ladder, also known as Doublets, was one of Erich and I’s most interesting brain teaser. Never heard of Word Ladder? Let’s get started!
The premise of the game is pretty simple, you’re given two words of the same length i.e. ‘cat’ and ‘dog’ the object of the game is to transform your starting word, one letter at a time, into the final word. The kicker is that each letter used to transform the word, must create a valid English word.
For example:
'cat' -> 'cag' //Invalid, cag is not an english word 'cat' -> 'dot' //Invalid, changed more than one letter 'cat' -> 'cot' //Valid 'cot' -> 'dot' //etc. 'cat' -> 'cot' -> 'dot' -> 'dog'
Pretty simple right? It takes 3 steps to get from ‘cat’ to ‘dog’. Note that this is not the only path to get from ‘cat’ to ‘dog’ only one path. Also, note that the path must be at least as long as the number of differences between the words, it can be longer. But the object of the game is to use the shortest path possible.
Let’s ramp up a bit and try a five letter word.
"which" -> "group"
A bit more difficult isn’t it? The shortest path between these two words is 13 steps.
"which" -> "whish" -> "whist" -> "wrist" -> "wrest" -> "prest" -> "prost" -> "pross" -> "gross" -> "gloss" -> "glost" -> "glout" -> "grout" -> "group"
Again, note that this is only one of the solutions for this particular problem.
So what makes this game interesting? Finding a solution for a problem set is a bit more difficult than the first glance gives.
Let’s outline our program parameters first, so we can get an idea as to what ALL of our solutions have to include.
- Input of 2 unique words of equal length
- Intermediate words must be preexisting dictionary words
- Intermediate words must be one letter different than the previous
- Solution should be the shortest path of intermediates between the 2 given words
Our outline gives a lot of hints as to how to think about a solution. We’re given 2 parameters, if they aren’t of equal length or not unique, then we have received invalid input. We should calculate the number of letters different the words are, as this is the minimum length for a solution. We’ll need a dictionary of words we can compare to our intermediates. Finally, we’ll since we’re getting the shortest length, a breadth-first search (or some variant) would be the simplest way of finding the shortest path.
Let’s try the easiest approach – brute force. For each word input, produce a list of all valid words by changing each letter of the word to each letter of the alphabet and cross-checking with our dictionary.
cat: aat, bat, cat, dat, eat, fat ... cat, cbt, cct, cdt, cft, cgt ... caa, cab, cac, cad, cae, caf ... Returns: bat, cat, eat, fat, cab bat: // Process cat: // Already Processed eat: // Process fat: // Process cab: // Process
You’ll see that the amount of data we’d have to process grows exponentially, not only do we have to process the initial word, we have to then process all permutations of them, and continue processing permutations until we reach then ending word.
The other issue is your algorithm will run into issues with larger words, or with words that don’t have paths between them.
Basically we do end up with a solution, but not one that’s efficient – it’ll work for those small use cases, but with unstable time complexities.
How can we make this better?
Well, we’ve missed a key requirement of this implementation – how do we store the dictionary? If you looked at the introduction to data structures post, you’d notice that this falls into the category of large data (oxford dictionary has 171,476 words), because of that, we have to find a way to access it in an efficient way as accessing is no longer an arbitrary time.
A trie data structure, is one made almost exclusively for dictionaries. There are several different ways to implement it, but the general concept is the same.
Starting with a tree structure:
For each word in the dictionary, split it into individual letters, traverse the tree down inserting the respective letter in order to the tree, adding nodes where necessary, on the last letter of the word, also insert a null node to that branch.
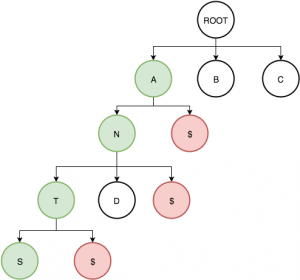
A trie is clever in the way that it works – in searching for a word, you can search for a prefix first. For instance, if we’re looking for the word ‘antalds’, in traversing the tree structure we find A -> N -> T -> A -> L -> ERROR, which means we can exit out early. To compare this with just a plain, unordered array: we just verified that a word doesn’t exist in 6 steps, whereas an array has a minimum of 1 step and a max of the dictionary size (171,476). Note here too that with an array, to verify a word doesn’t exist you would have to traverse the entire array. Basically a trie gives us an access time of any word in the dictionary with an upward bound of the length of the word.
What’s more is a dictionary is a relatively static structure too (we won’t be updating it every week or even every month). So instead of having to dynamically generate the trie structure for every client instance, we can pre-process our trie and load it into the application.
We’re going to take this implementation a step further though and add some additional pre-processing to our structure. If you remember from above, at some point we have to figure out valid permutations of a word, unfortunately there’s no getting around that part.
Interested? We’ll cover that in part 2.